I was wondering how PyTorch deals with those mathematically non-differentiable loss function for these days. So I have a brief summary here to share my findings.
TL;DR:
Basically, all the operations provided by PyTorch are ‘differentiable’. As for mathematically non-differentiable operations such as relu, argmax, mask_select and tensor slice, the elements at which gradients are not able to be calculated are set to gradient 0.
Investigation
Mathematically non-differentiable situation
For mathematically non-differentiable operations such as relu, argmax, mask_select and tensor slice, the elements at which gradients are not able to be calculated are set to gradient 0.
Take absolute function for example:
Absolute function is not differentiable at $x=0$, mathematically, but PyTorch set the gradient at this point to be 0. Here is a test:
1 2 3 4 5 6
import torch for i in range(11): x = torch.tensor([i-5], dtype=float, requires_grad=True) y = torch.abs(x) y.backward() print(x.grad)
This function isn’t analytically differentiable. However, at every point except 0, it is. In practice, for the purpose of gradient descent, it works well enough to treat the function as if it were differentiable. You’ll rarely be computing the gradient at precisely 0, and even if you do, it’s sufficient to handle things via a special case.
As for how to handle the special case, here is a good official example. The case could be specially treated in your backward function.
Well. “Keng” is actually the Pinyin of the Chinese character “坑”, meaning somgthing may mess you up. Here the “Keng” stands for the pitfall better to be aware of when using PyTorch in several specific situations.
I feel like to write something about ML in this blog, but do not actually have any topic at hand. “Keng” series will be a good start to summarize my experience in ML. Hope these experiences could help you :-).
Keng - 1
Problem
Generally, while using torch.nn.parallel.DistributedDataParallel , the code runs on multiple GPUs independently, meaning one process per GPU. The memory usage of each GPU should be close.
But I once found that a part of memory of gpu 0 was occupied by processes running on gpu 1-3 and caused CUDA out of memory error.
Cause
When loading a pretrained model with torch.load(), it put data to gpu 0.
Solution
An easy solution is to remap the data to cpu with torch.load('checkpoint.pth', map_location=torch.device('cpu'))
Plotly is one of the best tools I experienced to visualize data in Jupyter Notebook. While I am making a simple APP with JavaScript and Plotly.js, I found the API names of Plotly.py and Plotly.js are quite similar to each other. This new find inspired me to use Plotly.js in Jupyter Notebook, in which way I think is more flexible (maybe).
Method
Before start implementing anything, I searched for existing solutions. The method by HylaruCoder is one of the best (see Ref.[1]). According to HylaryCoder, RequireJS is a JS tool supported originally by Jupyter Notebook to dynamically load a JS module, which enable us to load plotls.js from the CDN address provided officially by Plotly.
Okay the code to load Plotly.js is like the following. By the way, the magic command to tell Jupyter Notebook to execute a JS script is %%javascript or %%js:
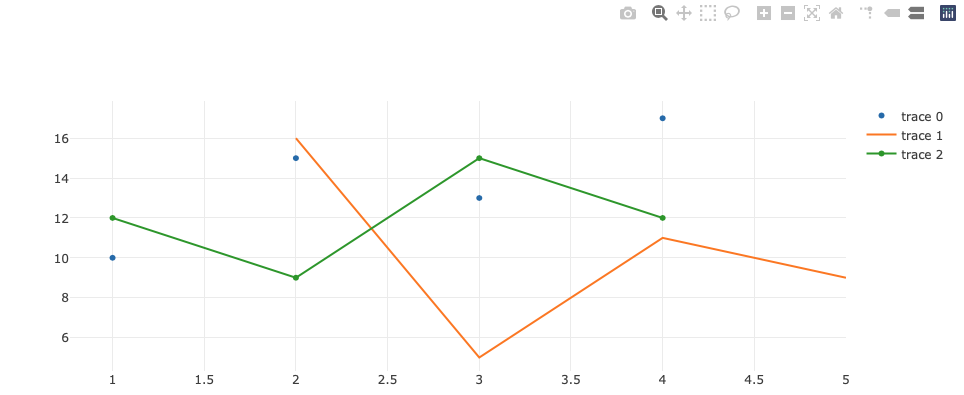
Then we’ll need a <div> element in the HTML page for sure, to contain the plot. The element is appended with command element.append(). Given the example data and call Plotly.js API like the following code, we could have the example figure plotted.
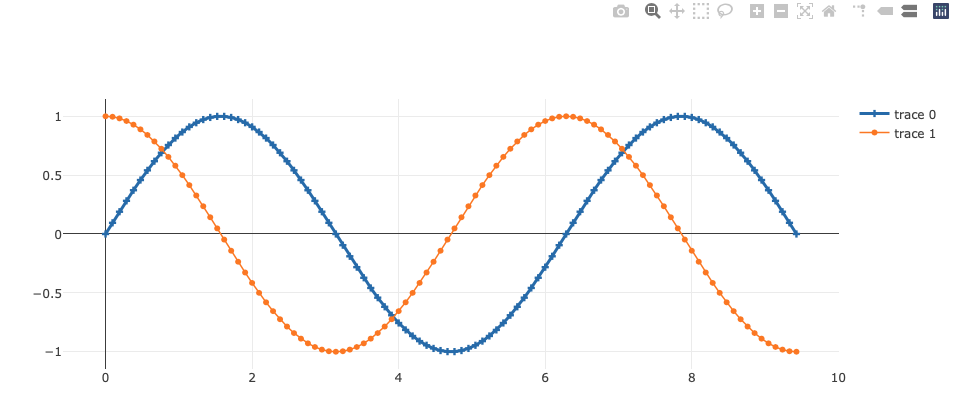
Wait, an error was thrown when I tried to execute the 2 code cells separately. The error message was from RequireJS, saying Failed to load resource: the server responded with a status of 404 (Not Found). Thanks to the answer from Ref.[2], the error disappeared after I merged the 2 code cells and execute. The plotted figure shoule like this:
In the example above, the example data for plotting is given in JS scripts. Then we’ll need to consider how to pass the processed data from Python cells to JS cells.
The answer is to use JSON (via the HTML page). Here’s the Python script to pass the generated data to HTML page ( window.plotly_json):
So in this script, 2 plot traces in dict type are generated (naming of variables here are very like those in Plotly.js). Then serialize the dictionary to JSON format and pass to window.plotly_json. (Notice: ndarray object is not be able to be serialized to JSON, use tolist() to conver to list in advance.)
Then the following script shows how to read the JSON data from HTML page and visualize with Plotly.js in the way introduced at the beginning.
按照HylaruCoder的方法,我把引入Plotls.js和使用Plotls.js分成了两个不同的Notebook Cell执行,但是一直显示空白div。通过查看JS console发现RequireJS一直在报这样的错误Failed to load resource: the server responded with a status of 404 (Not Found)。(满脸问号),幸好参考[2]建议我们把引入(require.config)和使用(require(['mymodule'], function( mymodule ))放在同一个Notebook Cell中使用,然后就成功了。图长这样:
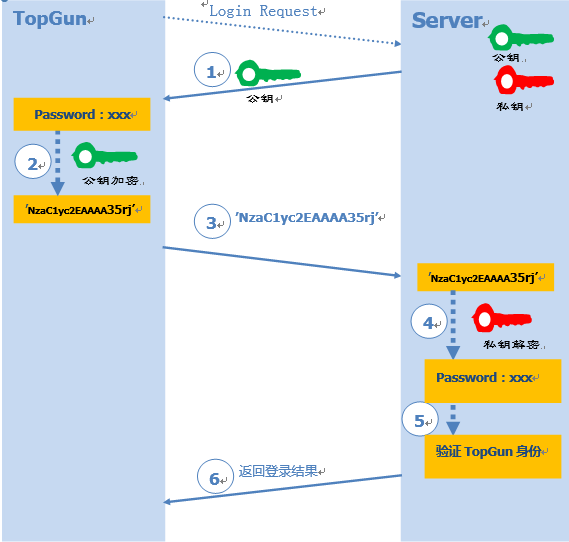
$ ssh-keygen -t rsa -C "your_email@example.com" -b 2048 Generating public/private rsa key pair. Enter file in which to save the key (/home/username/.ssh/id_rsa): /home/username/.ssh/GitHub_rsa Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/username/.ssh/GitHub_rsa. Your public key has been saved in /home/username/.ssh/GitHub_rsa.pub. The key fingerprint is: SHA256:GcK7ORvFzH6fzA7qPmnzBr1DOWho5cCVgIpLkh6VGb8 Fan@outlook.com The key's randomart image is: +---[RSA 2048]----+ | .+... . | | +o. o | | o.. oo.. | |+o. +*.o | |+.. E.=So . | |.. o== = | | .=..+oo | | +=o+= . | | .++=.o* | +----[SHA256]-----+
The authenticity of host 'hostname' can't be established. RSA key fingerprint is SHA256:nThbg6kXUpJWGl7E1IGOCspRomTxdCARLviKw6E5SY8. Are you sure you want to continue connecting (yes/no)?
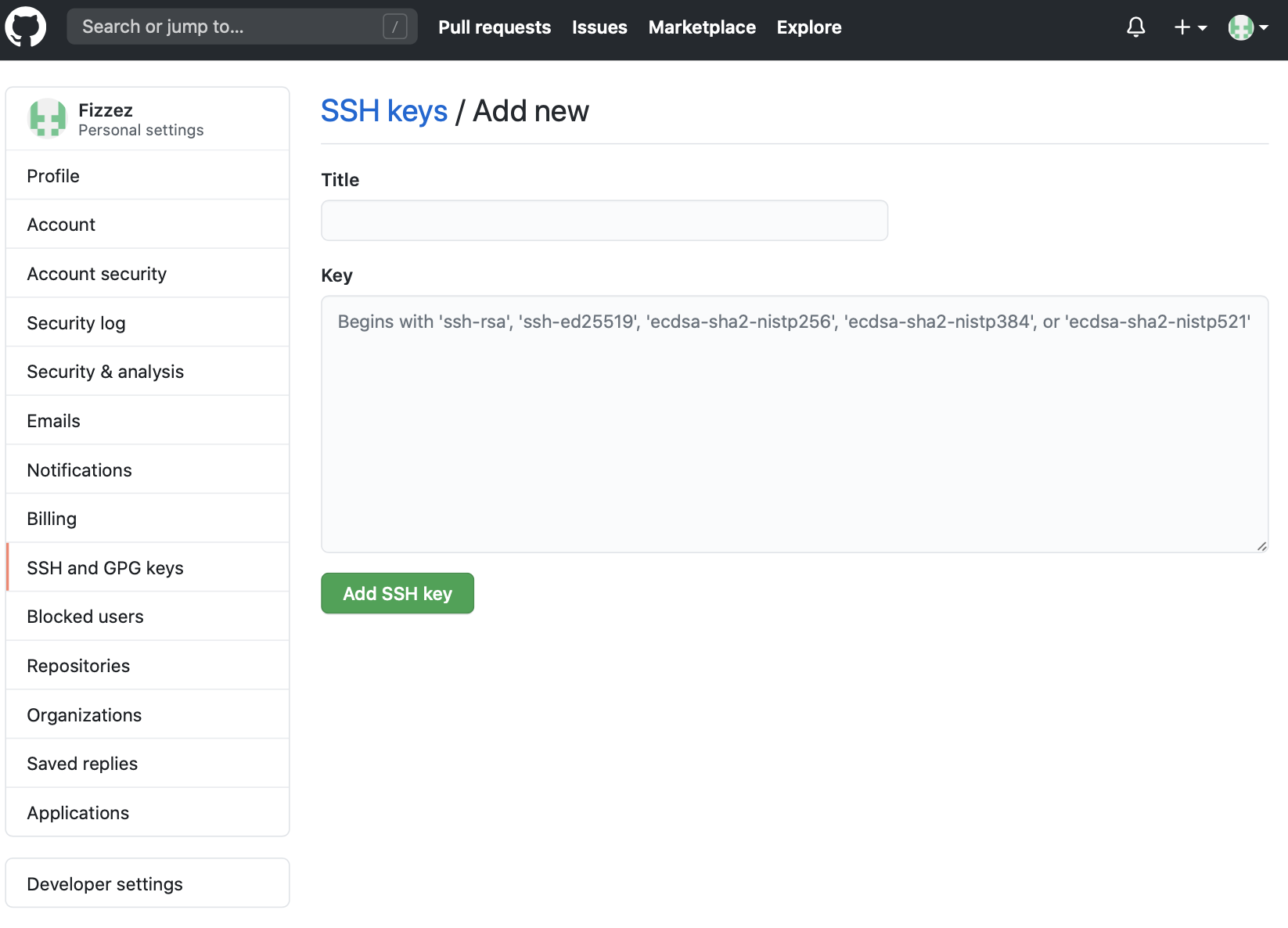
分别在两个Github账户的Settings - SSH and GPG keys页面添加SSH key。如下图所示,Key字段需要复制粘贴对应的github_user1_rsa.pub或者github_user2_rsa.pub公钥文件中的内容。
测试配置是否成功
使用以下命令测试配置是否成功:
1 2 3 4 5 6 7 8 9
# Address of github_user_1 ssh -T git@github_user_1.github.com # 出现如下内容,表示使用github_user_1的身份成功链接Github Hi github_user_1! You've successfully authenticated, but GitHub does not provide shell access.
# Address of github_user_2 ssh -T git@github_user_2.github.com # 出现如下内容,表示使用github_user_2的身份成功链接Github Hi github_user_2! You've successfully authenticated, but GitHub does not provide shell access.
Got a pandas DataFrame that has a column with slash-separated properties. I want to conver the properties to column-separated True or False values.
Like the following example. The DataFrame contains 5 persons’ information. The ‘characters’ column, in which slash-sepatared characters are contained, describing the personalities, is the target.
1 2 3 4 5 6
id gender characters 0 0 F active/earnest 1 1 M funny 2 2 F active/dedicated/earnest 3 3 F dedicated/disciplined 4 4 M active/disciplined
The result should look like the following. The slash-separated characters are firstly gathered to form the new columns, as a new view to personality, then appended right next to previous DataFrame. If the person has a specific character describe in ‘characters’ column, a True will be given in the corresponding new columns, else False.
1 2 3 4 5 6
id gender characters active earnest funny dedicated disciplined 0 0 F active/earnest True True False False False 1 1 M funny False False True False False 2 2 F active/dedicated/earnest True True False True False 3 3 F dedicated/disciplined False False False True True 4 4 M active/disciplined True False False False True
Solution
Split the ‘slash-separated properities’ to a list of properties.
>>> active earnest funny dedicated disciplined >>> 0 True True NaN NaN NaN >>> 1 NaN NaN True NaN NaN >>> 2 True True NaN True NaN >>> 3 NaN NaN NaN True True >>> 4 True NaN NaN NaN True
Concat the result to original DataFrame and fill nan.